Abstract
Coding agents built on LLMs often run synchronously: propose, wait, test, iterate. Recent trends suggest that parallel speculative generation, asynchronous messaging between agents, and dynamic scheduling can reduce wall-clock latency while preserving or improving solution quality. This project will build such mechanisms into a minimal coding-agent framework and evaluate the speed/quality trade-offs on standard code benchmarks under a fixed compute budget.
We connect this work to emerging parallel-coding practices, including subagent-style architectures (Anthropic) and end-to-end coding agents such as Devin, alongside speculative/medusa-style multi-branch decoding.
Background
The common agentic coding loop involves: prompt → code draft → run tests → repair → repeat. Two orthogonal accelerators are increasingly explored:
- Parallel speculative decoding: generate multiple plausible continuations in parallel, then select/merge based on fast heuristics or test feedback.
- Asynchronous multi-agent orchestration: allow tool calls, test runs, and critiques to proceed without global barriers; schedule work dynamically as results arrive.
For coding tasks, both ideas can be combined: fast parallel drafting plus an event-driven scheduler that routes failing cases to repair agents while successful drafts advance to verification.
Key Works
- Parallel Speculative Text Generation (PASTA), MIT CSAIL, 2025 — demonstrates parallel text generation for latency gains.
- M1-Parallel: Multi-Agent Parallel Framework, Tsinghua University, 2025 — asynchronous messaging across agent teams.
- MARCO: Multi-Agent Reinforcement Compiler Optimization, ETH Zürich, 2025 — division of labor between codegen and performance evaluators in a feedback loop.
- Asynchronous LLM Agents with Dynamic Scheduling, DeepMind, 2025 — event-driven plans and adaptive timing for multi-agent systems.
These links point to arXiv search queries; replace with canonical IDs once finalized.
Standards & Patterns
- Subagent architectures — hierarchical or role-based agents coordinating asynchronously; see Anthropic Research.
- End-to-end coding agents — continuous plan→code→test loops (e.g., Devin) with multi-threaded tool use.
- Speculative/Medusa-style decoding — branch-and-select or multi-head lookahead for fast drafting; e.g., speculative decoding and Medusa.
- Manus-style multi-agent coordination — reported agent frameworks emphasizing parallel tool calls. arXiv search
These are described as emerging practices; confirm precise sources and scope in the literature review.
Anthropic: Multi‑agent Research System
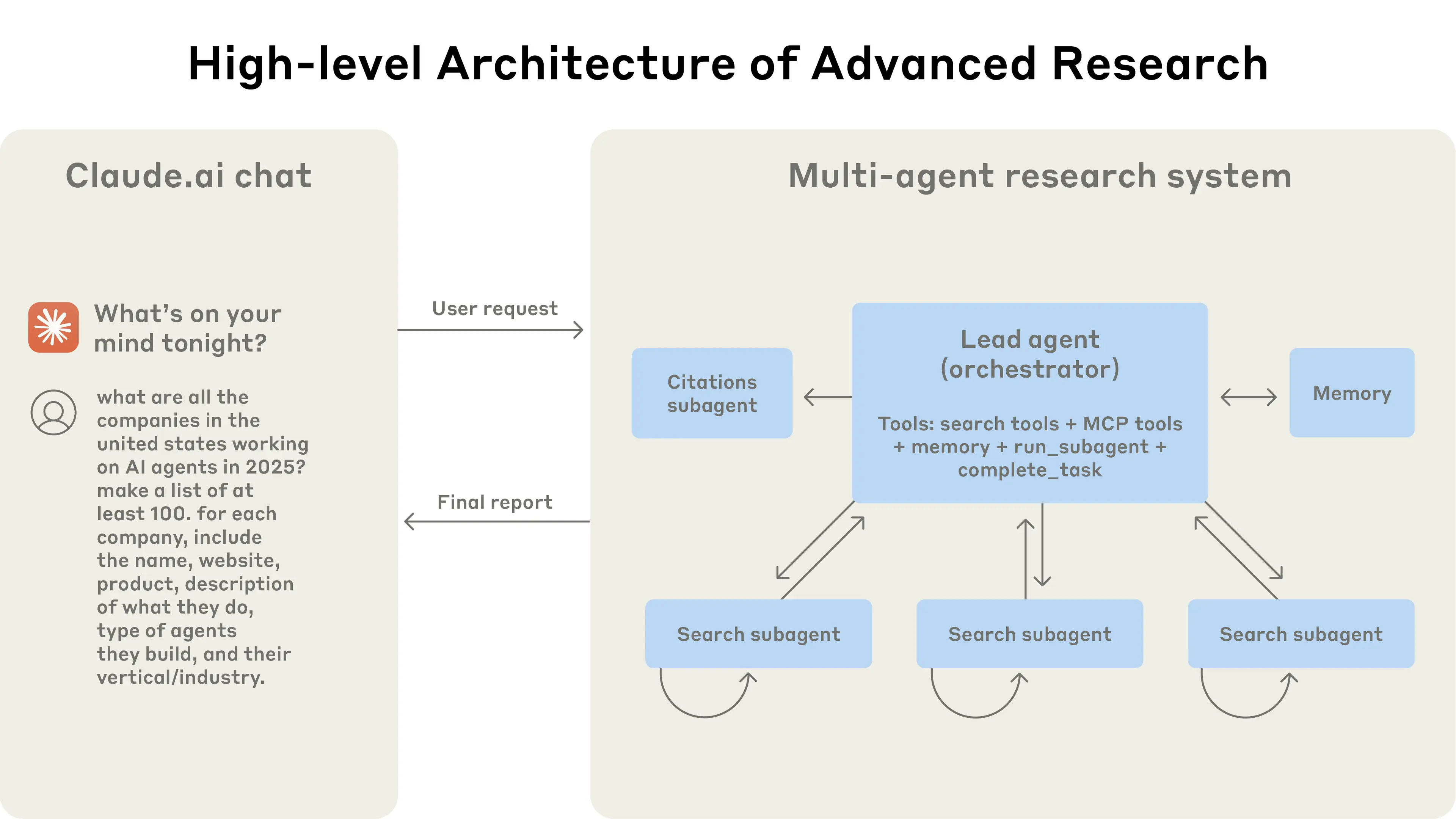
Multi‑agent Systems
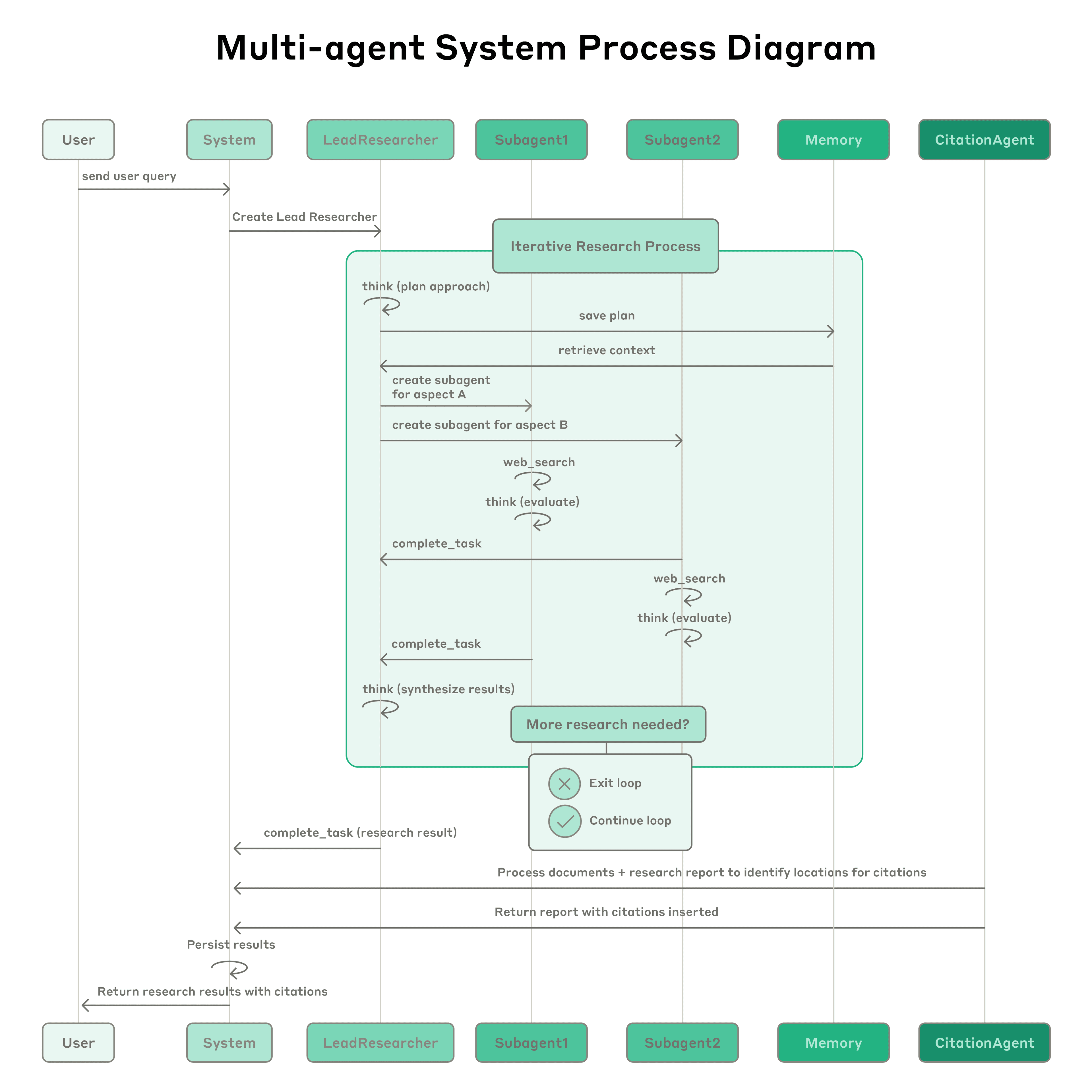
System Design
Minimal Coding-Agent Core
TaskRunner: loads a task (e.g., unit tests), provides I/O harness and sandboxed execution.DraftAgent: prompts an LLM to produce candidate patches or files.Judge: runs tests, collects signals (pass/fail, coverage, runtime), and emits events.Scheduler: event loop that assigns work to agents as results arrive; supports parallelism and backpressure.
Parallel/Async Strategies
- Parallel sampling: launch
kcandidates with different seeds/temps; pick best-by-tests or lightweight static checks. - Speculative merge: tree- or block-level merge using diffs; prefer minimal edits to pass tests.
- Asynchronous repair: failing candidates trigger targeted repair agents without blocking other candidates.
- Dynamic scheduling: maintain a work queue prioritized by observed utility (e.g., coverage gain, failing-test count, patch size).
Budget Control
- Enforce a fixed total token budget and parallelism cap
Pto ensure fair comparisons. - Record per-candidate costs: tokens in/out, test runtime, wall-clock.
loop while budget & tasks:
event = await next_event()
if event.type == TEST_RESULT and event.pass:
accept_and_stop(task)
else if event.type in {TEST_FAIL, STATIC_WARN}:
schedule(repair_agent(event.context))
else if idle_slots > 0:
schedule(draft_agent(temp=next_temp(), seed=next_seed()))
Experiments & Metrics
Datasets
- HumanEval (Python) and/or MBPP for unit-test-based evaluation.
- Optional: small subset of LeetCode-style problems reproduced locally with tests.
Baselines
- Synchronous loop: 1-at-a-time draft → test → repair.
- Naive parallel:
ksamples in parallel, pick best-by-tests, no repair.
Treatments
- Parallel sampling with repair (vary
k, temperature). - Asynchronous scheduling (vary queue policy, priorities).
- Speculative merge vs. winner-takes-all.
Metrics
- Quality: pass@1, pass@k (on held-out tasks).
- Latency: wall-clock to first pass; area-under-curve of cumulative solves vs time.
- Cost: tokens used, test-time CPU seconds, and peak parallelism.
Ablations
- Effect of parallelism
P ∈ {1,2,4,8}. - Dynamic vs FIFO scheduling.
- With vs without speculative merge.
Thesis Proposal (Bachelor)
Title. Asynchronous and Parallel Execution for LLM-Based Coding Agents
Research Question. How much can asynchronous scheduling and parallel generation reduce time-to-solution for coding tasks at a fixed compute/token budget, and what is the effect on solution quality?
Standardization Goal. Define and implement an open, practical standard for both benchmarking and developing multi-agent coding systems; alternatively, build a reference multi-agent system that consolidates the best-performing techniques from current research, to serve as a baseline for future comparisons.
Scope
- Implement a lightweight coding-agent framework (Python) with pluggable schedulers.
- Integrate one hosted/base LLM (e.g., local small model or API) for drafts and repairs.
- Support
k-way parallel sampling and simple speculative merge. - Run controlled experiments on HumanEval/MBPP subsets.
- Draft an initial spec for benchmarking and development interfaces (tasks, logs, metrics, traces) and evaluate whether a new reference multi-agent system is warranted based on observed best practices.
Deliverables
- Open-source repo with reproducible scripts.
- Report with latency–quality–cost curves and ablations.
- Engineering notes on scheduler design and pitfalls.
- Draft standard or reference implementation for multi-agent benchmarking/development.
Feasibility
- Runs on a single development laptop/server; tests are lightweight.
- Timeframe fits a 12–14 week bachelor project with weekly milestones.
Suggested Timeline (12–14 weeks)
This timeline is intentionally vague and will be updated throughout 2025 as the abstract and new research develops. Prep work begins November 2025 to finalize project scope and limitations by January; the thesis officially starts in January 2026 and is planned for delivery in May 2026.
Pre‑phase (Nov–Dec 2025 → early Jan 2026)
- Nov–Dec 2025: Deep literature scan, refine abstract, shortlist datasets and metrics, draft standardization plan (benchmarking/development interfaces), define risks and limitations.
- By early Jan 2026: Freeze scope and limitations; finalize evaluation protocol and baseline definitions; set up environment and data curation.
- Week 1–2 (approx. Jan 5–18, 2026): Literature refresh; lock tasks and metrics; implement evaluation harness and initial baselines.
- Week 3–4 (approx. Jan 19–Feb 1, 2026): Implement core framework and synchronous baseline; training/testing scaffolds.
- Week 5–6 (approx. Feb 2–15, 2026): Add parallel sampling and naive selection; run first comparisons.
- Week 7–8 (approx. Feb 16–Mar 1, 2026): Add asynchronous scheduler and repair agents; iterate on training/testing.
- Week 9–10 (approx. Mar 2–15, 2026): Speculative merge; tuning; ablations; begin writing methods.
- Week 11–12 (approx. Mar 16–29, 2026): Full runs; analysis; draft results and discussion.
- Optional +2 weeks (approx. Mar 30–Apr 12, 2026): Polishing, replication, additional dataset; finalize standard/reference implementation notes.
April–May 2026: Writing, editing, and submission; defense in May.
Risks & Mitigations
- API variability / rate limits: cache prompts and outputs; use small local model for smoke tests.
- Merge conflicts / regressions: run tests per candidate; keep edits minimal; revert on failure.
- Parallel thrash: enforce budgets; prioritize candidates yielding new coverage/failing-test fixes.
References
- Parallel Speculative Text Generation (PASTA), MIT CSAIL, 2025.
- M1-Parallel: Multi-Agent Parallel Framework, Tsinghua University, 2025.
- MARCO: Multi-Agent Reinforcement Compiler Optimization, ETH Zürich, 2025.
- Asynchronous LLM Agents with Dynamic Scheduling, DeepMind, 2025.
- Anthropic Research (subagents pattern).
- Cognition Labs: Introducing Devin.
- “Manus” multi-agent coding frameworks.
- Speculative Decoding for LLMs.
- Medusa: Multi-draft decoding heads.